ai tools
Llm Ops Governance Automation
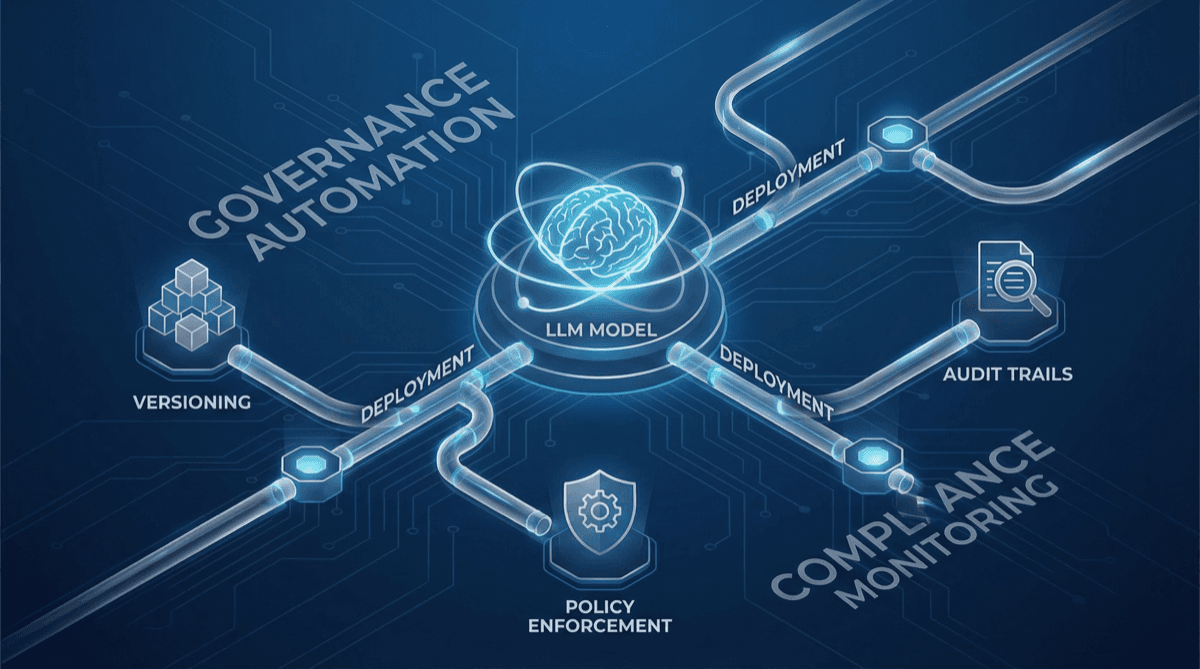
Technical automation blueprint for llm ops governance. Step-by-step guide for implementing AI-powered workflows.
2026-02-03
View Full Size
Technical automation blueprint for llm ops governance. Step-by-step guide for implementing AI-powered workflows.
2026-02-03