playbooks
Ai That Sticks Walls Framework
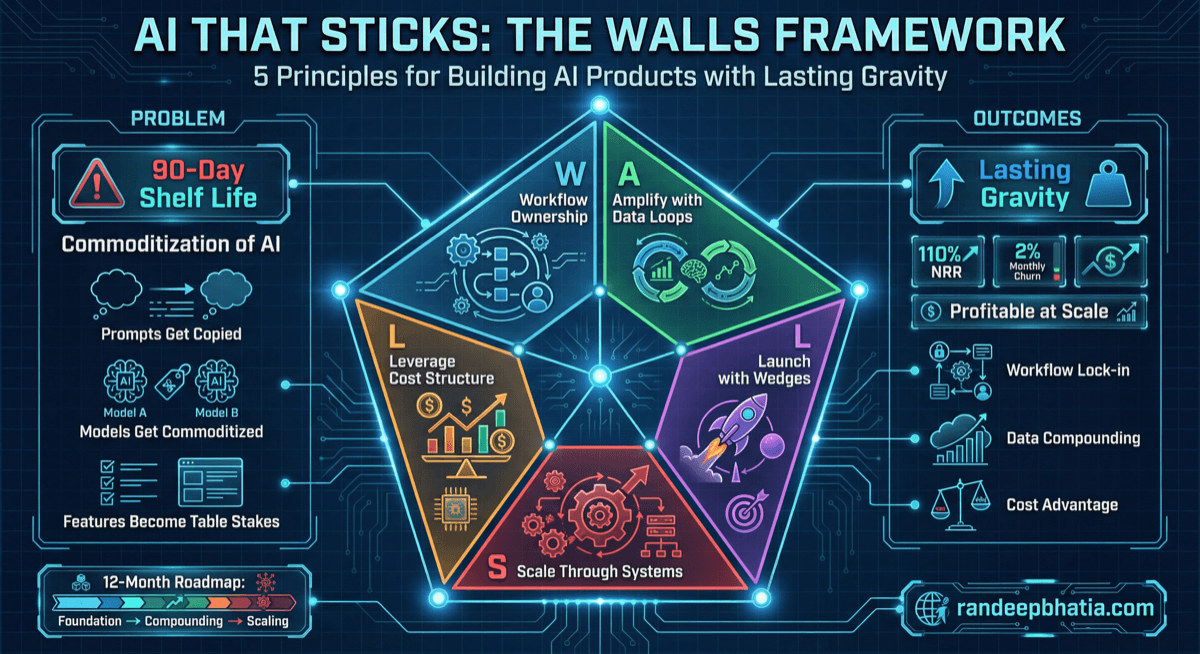
Strategic playbook for ai that sticks walls framework. Battle-tested framework for enterprise AI implementation.
View Full Size
Strategic playbook for ai that sticks walls framework. Battle-tested framework for enterprise AI implementation.