ai tools
Feature Feedback Analysis Automation
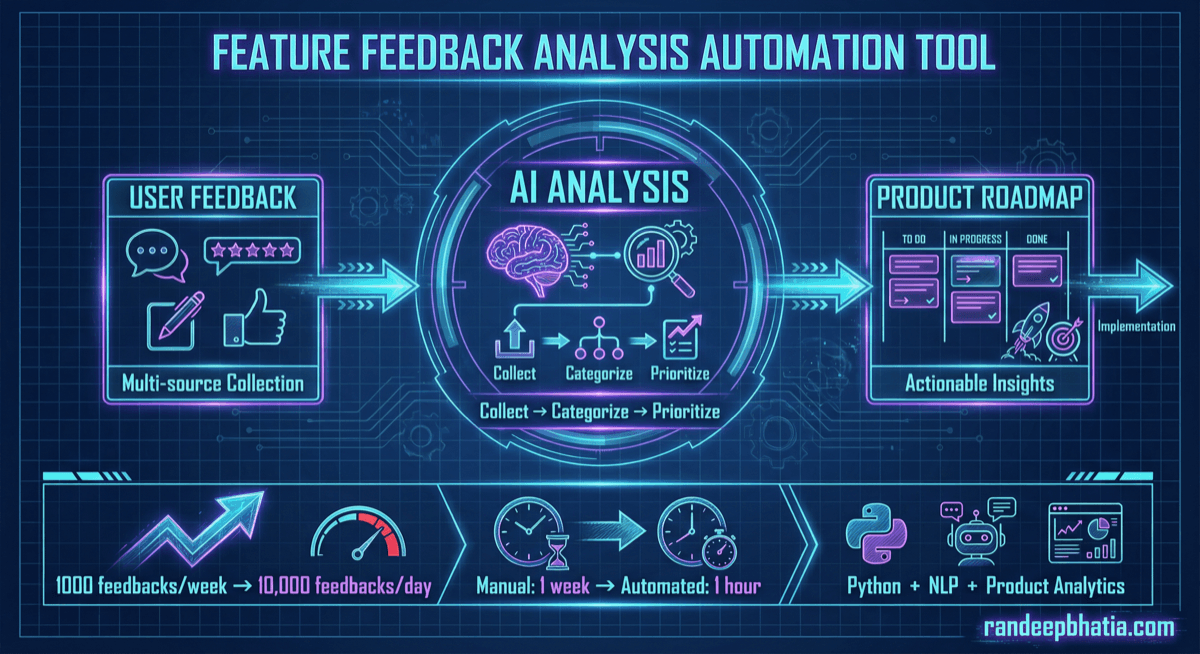
Technical automation blueprint for feature feedback analysis. Step-by-step guide for implementing AI-powered workflows.
2025-05-20
View Full Size
Technical automation blueprint for feature feedback analysis. Step-by-step guide for implementing AI-powered workflows.
2025-05-20