ai tools
Drug Trial Analysis Automation
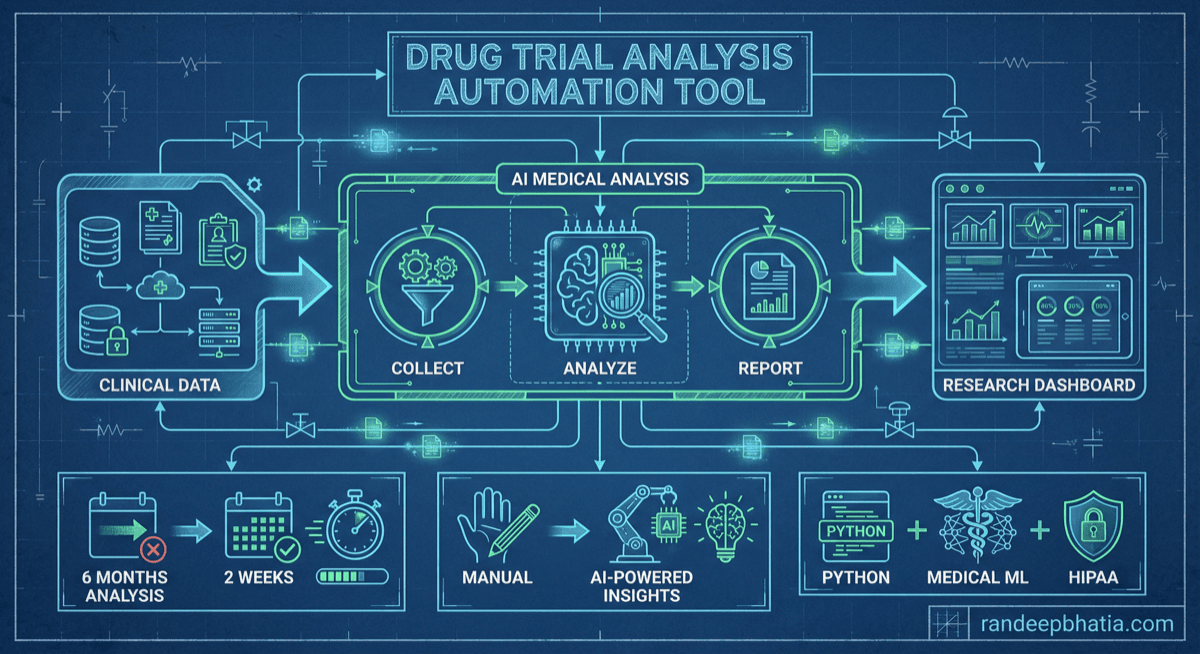
Technical automation blueprint for drug trial analysis. Step-by-step guide for implementing AI-powered workflows.
2025-08-26
View Full Size
Technical automation blueprint for drug trial analysis. Step-by-step guide for implementing AI-powered workflows.
2025-08-26