ai architecture
Voice Chat Support System Architecture
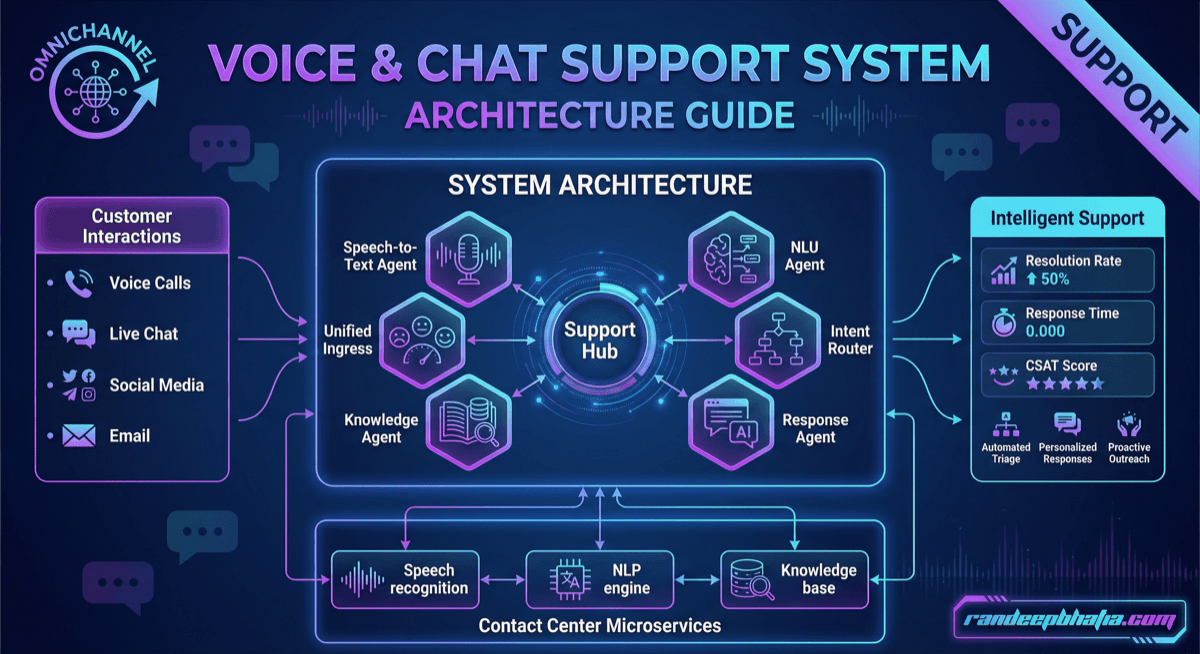
Production-ready system architecture for voice chat support. Includes component design, data flow patterns, scaling strategies, and security considerations.
2025-06-26
View Full Size
Production-ready system architecture for voice chat support. Includes component design, data flow patterns, scaling strategies, and security considerations.
2025-06-26